哈希表
哈希表(hash map),又称散列表,它通过建立键 key 与值 value 之间的映射,实现高效的元素查询。
在哈希表中进行增删查改的时间复杂度都是 O(1),非常高效。
常见操作
哈希表的常见操作包括:初始化、查询操作、添加键值对和删除键值对等,还有三种常用的遍历方式:遍历键值对、遍历键和遍历值,示例代码如下:
/* 初始化哈希表 */
hmap := make(map[int]string)
/* 添加操作 */
// 在哈希表中添加键值对 (key, value)
hmap[12836] = "ch"
hmap[15937] = "ak"
hmap[16750] = "hs"
hmap[13276] = "un"
hmap[10583] = "ot"
/* 查询操作 */
// 向哈希表中输入键 key ,得到值 value
name := hmap[15937]
/* 删除操作 */
// 在哈希表中删除键值对 (key, value)
delete(hmap, 10583)
/* 遍历哈希表 */
// 遍历键值对 key->value
for key, value := range hmap {
fmt.Println(key, "->", value)
}
// 单独遍历键 key
for key := range hmap {
fmt.Println(key)
}
// 单独遍历值 value
for _, value := range hmap {
fmt.Println(value)
}实现原理
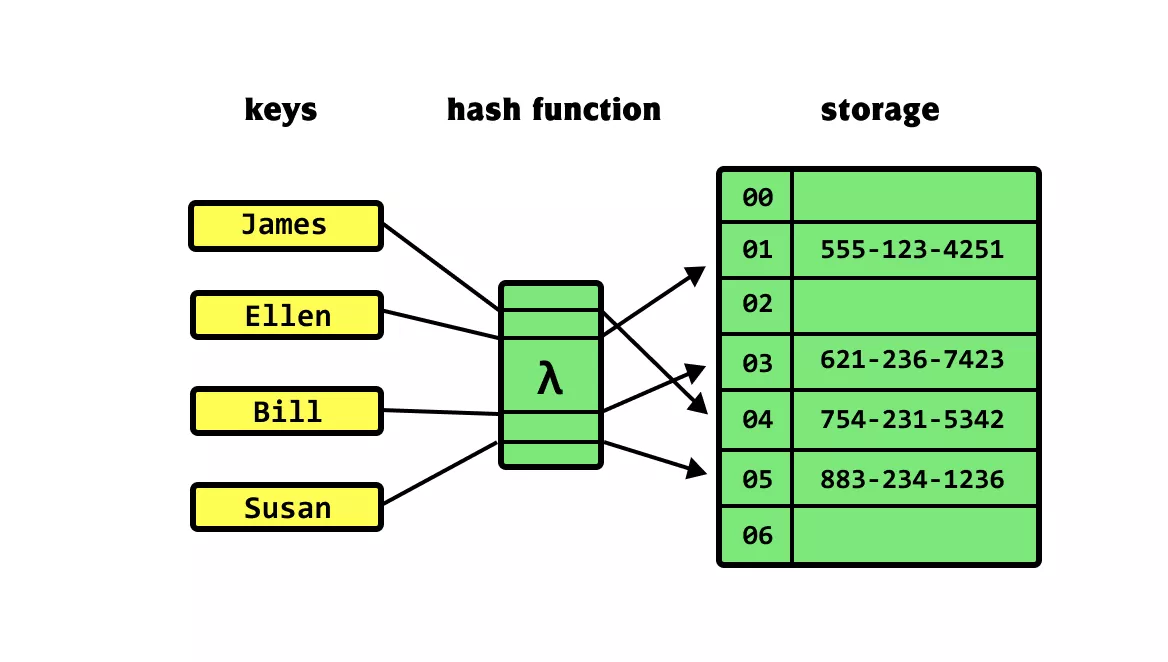
这里进行简单的模拟:仅用一个数组来实现哈希表。 在哈希表中,我们将数组中的每个空位称为桶(bucket),每个桶可存储一个键值对。因此,查询操作就是找到 key 对应的桶,并在桶中获取 value 。
我们可以通过哈希函数得到该 key 对应的键值对在数组中的存储位置。
哈希函数的计算过程分为以下两步。
通过某种哈希算法 hash() 计算得到哈希值。 将哈希值对桶数量(数组长度)capacity 取模,从而获取该 key 对应的数组索引 index 。
index = hash(key) % capacity设数组长度 capacity = 100、哈希算法 hash(key) = key ,易得哈希函数为 key % 100。
/* 键值对 */
type pair struct {
key int
val string
}
/* 基于数组实现的哈希表 */
type arrayHashMap struct {
buckets []*pair
}
/* 初始化哈希表 */
func newArrayHashMap() *arrayHashMap {
// 初始化数组,包含 100 个桶
buckets := make([]*pair, 100)
return &arrayHashMap{buckets: buckets}
}
/* 哈希函数 */
func (a *arrayHashMap) hashFunc(key int) int {
index := key % 100
return index
}
/* 查询操作 */
func (a *arrayHashMap) get(key int) string {
index := a.hashFunc(key)
pair := a.buckets[index]
if pair == nil {
return "Not Found"
}
return pair.val
}
/* 添加操作 */
func (a *arrayHashMap) put(key int, val string) {
pair := &pair{key: key, val: val}
index := a.hashFunc(key)
a.buckets[index] = pair
}
/* 删除操作 */
func (a *arrayHashMap) remove(key int) {
index := a.hashFunc(key)
// 置为 nil ,代表删除
a.buckets[index] = nil
}
/* 获取所有键对 */
func (a *arrayHashMap) pairSet() []*pair {
var pairs []*pair
for _, pair := range a.buckets {
if pair != nil {
pairs = append(pairs, pair)
}
}
return pairs
}
/* 获取所有键 */
func (a *arrayHashMap) keySet() []int {
var keys []int
for _, pair := range a.buckets {
if pair != nil {
keys = append(keys, pair.key)
}
}
return keys
}
/* 获取所有值 */
func (a *arrayHashMap) valueSet() []string {
var values []string
for _, pair := range a.buckets {
if pair != nil {
values = append(values, pair.val)
}
}
return values
}
/* 打印哈希表 */
func (a *arrayHashMap) print() {
for _, pair := range a.buckets {
if pair != nil {
fmt.Println(pair.key, "->", pair.val)
}
}
}哈希冲突
从本质上看,哈希函数的作用是将所有 key 构成的输入空间映射到数组所有索引构成的输出空间,而输入空间往往远大于输出空间。因此,理论上一定存在“多个输入对应相同输出”的情况。
我们将这种多个输入对应同一输出的情况称为哈希冲突(hash collision)。哈希冲突会导致查询结果错误,严重影响哈希表的可用性。
容易想到,哈希表容量 n 越大,多个 key 被分配到同一个桶中的概率就越低,冲突就越少。因此,我们可以通过扩容哈希表来减少哈希冲突。 此方法简单粗暴且有效,但效率太低,因为哈希表扩容需要进行大量的数据搬运与哈希值计算。为了提升效率,我们可以采用以下策略。
- 改良哈希表数据结构,使得哈希表可以在出现哈希冲突时正常工作。
- 仅在必要时,即当哈希冲突比较严重时,才执行扩容操作。
链式地址
在原始哈希表中,每个桶仅能存储一个键值对。链式地址(separate chaining)将单个元素转换为链表,将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。
基于链式地址实现的哈希表的操作方法发生了以下变化。
- 查询元素:输入 key ,经过哈希函数得到桶索引,即可访问链表头节点,然后遍历链表并对比 key 以查找目标键值对。
- 添加元素:首先通过哈希函数访问链表头节点,然后将节点(键值对)添加到链表中。
- 删除元素:根据哈希函数的结果访问链表头部,接着遍历链表以查找目标节点并将其删除。
链式地址存在以下局限性。
- 占用空间增大:链表包含节点指针,它相比数组更加耗费内存空间。
- 查询效率降低:因为需要线性遍历链表来查找对应元素。
我们来看一个链式地址哈希表的简单实现,为了简洁代码,使用动态数组代替链表。
/* 链式地址哈希表 */
type hashMapChaining struct {
size int // 键值对数量
capacity int // 哈希表容量
loadThres float64 // 触发扩容的负载因子阈值
extendRatio int // 扩容倍数
buckets [][]pair // 桶数组
}
/* 构造方法 */
func newHashMapChaining() *hashMapChaining {
buckets := make([][]pair, 4)
for i := 0; i < 4; i++ {
buckets[i] = make([]pair, 0)
}
return &hashMapChaining{
size: 0,
capacity: 4,
loadThres: 2.0 / 3.0,
extendRatio: 2,
buckets: buckets,
}
}
/* 哈希函数 */
func (m *hashMapChaining) hashFunc(key int) int {
return key % m.capacity
}
/* 负载因子 */
func (m *hashMapChaining) loadFactor() float64 {
return float64(m.size) / float64(m.capacity)
}
/* 查询操作 */
func (m *hashMapChaining) get(key int) string {
idx := m.hashFunc(key)
bucket := m.buckets[idx]
// 遍历桶,若找到 key ,则返回对应 val
for _, p := range bucket {
if p.key == key {
return p.val
}
}
// 若未找到 key ,则返回空字符串
return ""
}
/* 添加操作 */
func (m *hashMapChaining) put(key int, val string) {
// 当负载因子超过阈值时,执行扩容
if m.loadFactor() > m.loadThres {
m.extend()
}
idx := m.hashFunc(key)
// 遍历桶,若遇到指定 key ,则更新对应 val 并返回
for i := range m.buckets[idx] {
if m.buckets[idx][i].key == key {
m.buckets[idx][i].val = val
return
}
}
// 若无该 key ,则将键值对添加至尾部
p := pair{
key: key,
val: val,
}
m.buckets[idx] = append(m.buckets[idx], p)
m.size += 1
}
/* 删除操作 */
func (m *hashMapChaining) remove(key int) {
idx := m.hashFunc(key)
// 遍历桶,从中删除键值对
for i, p := range m.buckets[idx] {
if p.key == key {
// 切片删除
m.buckets[idx] = append(m.buckets[idx][:i], m.buckets[idx][i+1:]...)
m.size -= 1
break
}
}
}
/* 扩容哈希表 */
func (m *hashMapChaining) extend() {
// 暂存原哈希表
tmpBuckets := make([][]pair, len(m.buckets))
for i := 0; i < len(m.buckets); i++ {
tmpBuckets[i] = make([]pair, len(m.buckets[i]))
copy(tmpBuckets[i], m.buckets[i])
}
// 初始化扩容后的新哈希表
m.capacity *= m.extendRatio
m.buckets = make([][]pair, m.capacity)
for i := 0; i < m.capacity; i++ {
m.buckets[i] = make([]pair, 0)
}
m.size = 0
// 将键值对从原哈希表搬运至新哈希表
for _, bucket := range tmpBuckets {
for _, p := range bucket {
m.put(p.key, p.val)
}
}
}
/* 打印哈希表 */
func (m *hashMapChaining) print() {
var builder strings.Builder
for _, bucket := range m.buckets {
builder.WriteString("[")
for _, p := range bucket {
builder.WriteString(strconv.Itoa(p.key) + " -> " + p.val + " ")
}
builder.WriteString("]")
fmt.Println(builder.String())
builder.Reset()
}
}当链表很长时,查询效率 O(n) 很差。此时可以将链表转换为“AVL 树”或“红黑树”,从而将查询操作的时间复杂度优化至 O(logn)。
开放寻址
开放寻址(open addressing)不引入额外的数据结构,而是通过“多次探测”来处理哈希冲突,探测方式主要包括线性探测、平方探测和多次哈希等。
线性探测采用固定步长的线性搜索来进行探测,其操作方法与普通哈希表有所不同。
- 插入元素:通过哈希函数计算桶索引,若发现桶内已有元素,则从冲突位置向后线性遍历(步长通常为 1),直至找到空桶,将元素插入其中。
- 查找元素:若发现哈希冲突,则使用相同步长向后进行线性遍历,直到找到对应元素,返回 value 即可;如果遇到空桶,说明目标元素不在哈希表中,返回 None 。
值得注意的是,我们不能在开放寻址哈希表中直接删除元素。这是因为删除元素会在数组内产生一个空桶 None ,而当查询元素时, 线性探测到该空桶就会返回,因此在该空桶之下的元素都无法再被访问到,程序可能误判这些元素不存在。 可以采用懒删除(lazy deletion)机制:它不直接从哈希表中移除元素,而是利用一个常量 TOMBSTONE 来标记这个桶。
以下代码实现了一个包含懒删除的开放寻址(线性探测)哈希表。为了更加充分地使用哈希表的空间,我们将哈希表看作一个“环形数组”,当越过数组尾部时,回到头部继续遍历。
/* 开放寻址哈希表 */
type hashMapOpenAddressing struct {
size int // 键值对数量
capacity int // 哈希表容量
loadThres float64 // 触发扩容的负载因子阈值
extendRatio int // 扩容倍数
buckets []pair // 桶数组
removed pair // 删除标记
}
/* 构造方法 */
func newHashMapOpenAddressing() *hashMapOpenAddressing {
buckets := make([]pair, 4)
return &hashMapOpenAddressing{
size: 0,
capacity: 4,
loadThres: 2.0 / 3.0,
extendRatio: 2,
buckets: buckets,
removed: pair{
key: -1,
val: "-1",
},
}
}
/* 哈希函数 */
func (m *hashMapOpenAddressing) hashFunc(key int) int {
return key % m.capacity
}
/* 负载因子 */
func (m *hashMapOpenAddressing) loadFactor() float64 {
return float64(m.size) / float64(m.capacity)
}
/* 查询操作 */
func (m *hashMapOpenAddressing) get(key int) string {
idx := m.hashFunc(key)
// 线性探测,从 index 开始向后遍历
for i := 0; i < m.capacity; i++ {
// 计算桶索引,越过尾部则返回头部
j := (idx + i) % m.capacity
// 若遇到空桶,说明无此 key ,则返回 null
if m.buckets[j] == (pair{}) {
return ""
}
// 若遇到指定 key ,则返回对应 val
if m.buckets[j].key == key && m.buckets[j] != m.removed {
return m.buckets[j].val
}
}
// 若未找到 key ,则返回空字符串
return ""
}
/* 添加操作 */
func (m *hashMapOpenAddressing) put(key int, val string) {
// 当负载因子超过阈值时,执行扩容
if m.loadFactor() > m.loadThres {
m.extend()
}
idx := m.hashFunc(key)
// 线性探测,从 index 开始向后遍历
for i := 0; i < m.capacity; i++ {
// 计算桶索引,越过尾部则返回头部
j := (idx + i) % m.capacity
// 若遇到空桶、或带有删除标记的桶,则将键值对放入该桶
if m.buckets[j] == (pair{}) || m.buckets[j] == m.removed {
m.buckets[j] = pair{
key: key,
val: val,
}
m.size += 1
return
}
// 若遇到指定 key ,则更新对应 val
if m.buckets[j].key == key {
m.buckets[j].val = val
return
}
}
}
/* 删除操作 */
func (m *hashMapOpenAddressing) remove(key int) {
idx := m.hashFunc(key)
// 遍历桶,从中删除键值对
// 线性探测,从 index 开始向后遍历
for i := 0; i < m.capacity; i++ {
// 计算桶索引,越过尾部则返回头部
j := (idx + i) % m.capacity
// 若遇到空桶,说明无此 key ,则直接返回
if m.buckets[j] == (pair{}) {
return
}
// 若遇到指定 key ,则标记删除并返回
if m.buckets[j].key == key {
m.buckets[j] = m.removed
m.size -= 1
}
}
}
/* 扩容哈希表 */
func (m *hashMapOpenAddressing) extend() {
// 暂存原哈希表
tmpBuckets := make([]pair, len(m.buckets))
copy(tmpBuckets, m.buckets)
// 初始化扩容后的新哈希表
m.capacity *= m.extendRatio
m.buckets = make([]pair, m.capacity)
m.size = 0
// 将键值对从原哈希表搬运至新哈希表
for _, p := range tmpBuckets {
if p != (pair{}) && p != m.removed {
m.put(p.key, p.val)
}
}
}
/* 打印哈希表 */
func (m *hashMapOpenAddressing) print() {
for _, p := range m.buckets {
if p != (pair{}) {
fmt.Println(strconv.Itoa(p.key) + " -> " + p.val)
} else {
fmt.Println("nil")
}
}
}除了线性探测海外,还有两个常见的探测方式:平方探测和多次哈希。
平方探测与线性探测类似,都是开放寻址的常见策略之一。当发生冲突时,平方探测不是简单地跳过一个固定的步数,而是跳过“探测次数的平方”的步数,即 1、4、9... 步。
多次哈希顾名思义,多次哈希方法使用多个哈希函数。当发生冲突时,我们可以通过多个哈希函数来计算多个哈希值,然后逐个尝试,直到找到空桶。与线性探测相比,多次哈希方法不易产生聚集,但多个哈希函数会带来额外的计算量。
请注意,开放寻址(线性探测、平方探测和多次哈希)哈希表都存在“不能直接删除元素”的问题。
编程语言
各种编程语言采取了不同的哈希表实现策略,下面举几个例子。
- Python 采用开放寻址。字典 dict 使用伪随机数进行探测。
- Java 采用链式地址。自 JDK 1.8 以来,当 HashMap 内数组长度达到 64 且链表长度达到 8 时,链表会转换为红黑树以提升查找性能。
- Go 采用链式地址。Go 规定每个桶最多存储 8 个键值对,超出容量则连接一个溢出桶;当溢出桶过多时,会执行一次特殊的等量扩容操作,以确保性能。